Praktyczne zostosowanie Gita - lokalnie
System kontroli wersji jest znany przede wszystkim informatykom a w szczególności programistom. Myślę jednak, że bardzo często nawet osoby piszące oprogramowanie nie dostrzegają większej konieczności stosowania gita poza obowiązkami zawodowymi. Przez długi czas sam również nie widziałem potrzeby zastosowania tego narzędzia. Jako że nie jestem programistą, to może wydawać się słuszne.
Z ciekawości jednak postanowiłem zapoznać się z Git-em. Nie jest to na pewno oprogramowanie, które zachęca nie tylko do użytkowania, ale również samej instalacji. Korzystanie z linii komend wydaje się wyjątkowo archaiczne i odstraszające. Na szczęście wklepywanie poleceń nie jest absolutną koniecznością. Do dyspozycji jest także graficzna wersja tzw. GUI. Prawdę mówiąc, okienkowa wersja gita również nie jest zbyt atrakcyjna oraz "user friendly".
Tylko co to jest właściwie GIT, do czego służy, jak mogę go wykorzystać ?. Popularne wyjaśnienia to rozproszony system kontroli wersji, śledzenie historii zmian w plikach ... Jak to brzmi ? lub ile osób zrozumie takie określenia ?. Teksty trochę jak z tłumaczenie z obcego języka.
Osobiście zastosowałbym doświadczenie wyniesione z gier komputerowych. Sposób porównania nie jest idealny. Myślę jednak, że umożliwia uchwycenie idei. Prawdopodobnie niemal wszystkie gry komputerowe mają możliwość zapisu aktualnego stanu gry. Jednocześnie zawsze możesz wrócić do jednego z poprzednich save-ów, nawet bardzo odległych i zmienić kierunek rozgrywki.
Podobnie jest z GIT-em robisz save-a, kiedy uznasz to za stosowne lub też wybierasz dawnego loada i nad nim pracujesz. Łatwo zauważyć, że takich zeszłych stanów może być bardzo dużo. Dlatego od samego początku warto nauczyć się dodawać sensowne i logiczne komentarze do każdego sava. Pozwoli to całkiem dobrze orientować się w gąszczu stworzonych commitów i branchów (savów).
Taka mała dygresja, zastosowałem angielska terminologie, czyli save oznacza zapis stanu a load to zwyczajnie wczytanie wcześniej zapisanego stanu gry.
W tym krótkim poradniku pragnę zaprezentować praktyczne zastosowanie gita do własnych celów. Przede wszystkim lokalnie, na dysku twardym. Oczywiście możliwe jest także podpięcie się do zdalnego repozytorium w celu archiwizacji bądź zabezpieczenia danych.
Warto jednak pamiętać, że na gitlabie darmowe konta oferują publiczne repozytoria, czyli są dostępne dla każdego (prywatne repozytoria oferuje GitLab). Dla niewtajemniczonych repozytorium to miejsce przeznaczone do zapisu jednego projektu. Folder gdzie znajdują się wszystkie pliki programu, nad którym pracujesz wraz z całą historią zmian.
Oczywiście projekt to nie koniecznie musi oznaczać program. Może to być np. Książka, prezentacja w power point, plik/i excela, jednym słowem cokolwiek wymagające wprowadzania zmian podczas pracy (updaty, ulepszenia ...)
Zabawę z gitem proponuję od pobrania najbardziej popularnego oprogramowania do zarządzenia systemem wersji, czyligit-a (). Github jest tak modny, że po wpisaniu w google system kontroli wersji zajmuje większość pozycji. Oczywiście jest to jedyne oprogramowanie pozwalające na pracę z CVS. Bardziej zainteresowani mogą spróbować szczęścia z np. Mercurial (podobno łatwiejszy do nauki i pracy), CVS, SVN, Monotone, Bazaar (https://en.wikipedia.org/wiki/List_of_version-control_software) ...
Proponuję pobrać git-bash (https://gitforwindows.org). Podobnie jak z mnóstwem innych instalatorów także i tutaj podczas instalacji Git-a padnie kilka pytań. Do podstawowych zadań nie potrzeba niczego specjalnego zaznaczać tylko zgodzić się na domyślną konfigurację, ewentualnie wybrać eksperymentalne dodatki.
Na początek stwórz katalog/folder gdzie będziesz zapisywał swoje pliki np. GIT-TRAINING. W tym celu uruchom CommandPrompt w swoim katalogu. Następnie zainicjuj GIT-a poleceniem git init:
INICJACJA GITA

PODSTAWOWY KONFIG
Warto dokonać pewnych zmian w podstawowej konfiguracji gita. Nie jest to wprawdzie koniecznie, ale dobrze jest mieć świadomość o takich rozwiązaniach. Przede wszystkim ustawić domyślnego użytkownika. Czyli kto będzie wykonywał comity (savy,loady). Domyślną konfigurację zobaczysz po wpisaniu w terminalu komendy (obecnego użytkownika — jegoemail oraz nazwę ) git --list:


Aby zmienić powyższe ustawienia, w terminalu wpisz następujące polecenia:
$ git config --globaluser.name "Jan Kowalski"
$ git config --globaluser.email jonaKowalski@cosTam.com
Dla większej wygody można również pokusić się o odpowiednią konfigurację domyślnego edytora (podaj ścieżkę dostępu do swojego ulubionego narzędzia):
git config --global core.editor "C:\Program Files ...\gedit.exe"
GIT PRAKTYCZNIE - LOKALNIE
Myślę, że powyższe ustawienia GIT-a powinny wystarczyć. Teraz zajmiemy się już praktyką ;).
Powiedzmy, że piszę ksiażkę (plik wordowski--> docx).
Plik w tej postaci zapisz na dysku w folderze np. GIT-TRAINING. Początkowy status repozytorium zapiszę (zrobię sava) pierwszym commitem. Dobrym nawykiem jest sprawdzenie stanu naszego repozytorium, zawsze przed każdą zmianą (komendą):
git status
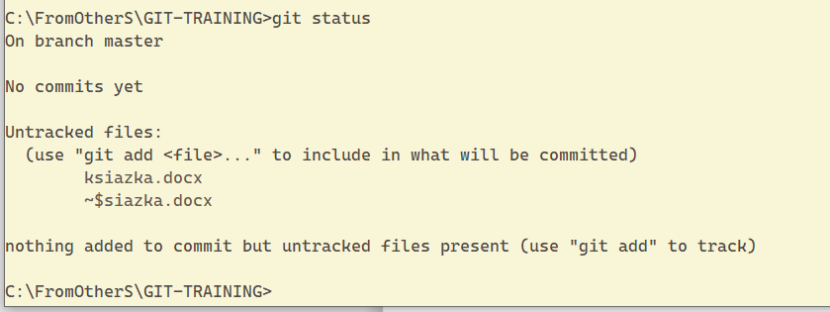
Jak widać, nie zostały wykonane żadne commity. Program wyświetla także najbardziej przydatne informacje. Obecny status to tylko pliki nieśledzone. Dodatkowo na tacy podane jest polecenie, w jaki sposób uwzględnić każdy (plik) w przyszłym commicie.
Pliki w git-cie mogą być w dwóch stanach — nieśledzone (sytuacja wyżej), w stanie zwanym staged (czyli śledzone). Dobrze jest jeszcze zaakcentować stan committed (zapisane — czyli zrobiony save - również śledzone). Wszystkie pliki, które chcemy (zapisać/wykonać sava/ committed ) muszą najpierw zostać wrzucone do stanu staged komendą:
git add ksiazka.docx
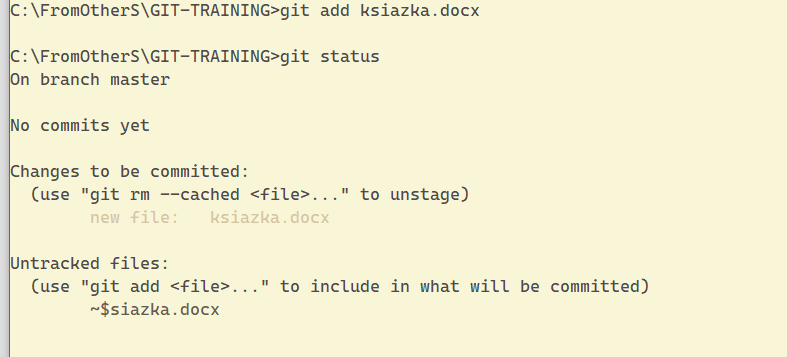
Gdy już dodasz plik do stanu przejściowego -> staged, wpisz git status, aby zorientować się jak wygląda stan twojego repozytorium.
Aktualnie mamy wyraźnie wszystkie 3 stany podane, czyli, brak committed files (zapisanych/wykonanych savów), plik książka w stanie staged oraz pliki nieśledzone ~$siazka.docx.
Git podaje także komendę jak usunąć plik ze stanu staged (gdy uznasz, że popełniłeś błąd i nie chcesz zapisywać tego pliku) --> git rm--cachedksiazka.docx.
Teraz już możesz wykonać sava pliku (czyli committ-a) : git commit -m ”Twój komentarz / nazwa zapisu/sava” np. -->
git commit -m ”Napisalem rozdzial pierwszy”
Pamiętaj!, jeżeli pomiędzy komendą add plik <--a--> commit -m "komentarz", wykonasz jakieś zmiany w pliku, to nowe uaktualnienia nie zostaną uwzględnione w commit-cie (tylko modyfikacje do momentu przed "add plik" ).
Jeśli pracujesz z większą ilością plików, nie musisz każdego z nich dodawać osobno. Wszystkie pliki można przesunąć do stanu staged jednym poleceniem git add * (dodaje również katalogi z całą zawartością) lub git add . (dodaje tylko pliki w aktualnej ścieżce dostępu, jednocześnie pomija wszystkie pliki rozpoczynające się od kropki).
Stan staged może być trochę irytujący, zwłaszcza jeśli używasz git-a do celów prywatnych na niewielkiej ilości plików. Na to jest jednak sposób. Wystarczy, że uzyjeszgit-a w ten sposób i pominiesz fazę staged:
git commit -am ”Twoj komentarz”
Idziemy dalej, dopisałem kilka paragrafów do rozdziału pierwszego i znów pragnę zrobić sava.

Wykonuję więc jeszcze raz sekwencje:
git status
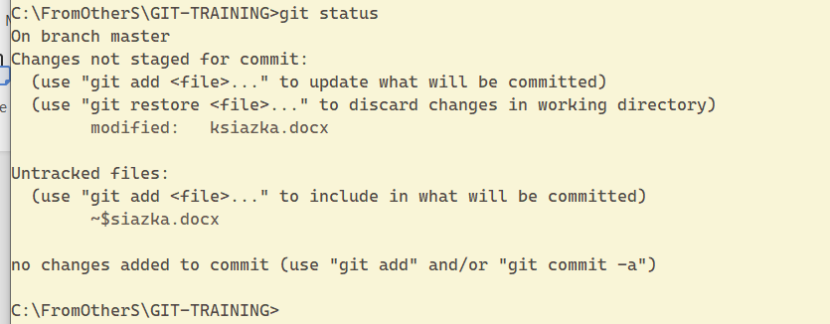
Zgodnie z przewidywaniami plik ksiazka.docx został zmieniony. Jak już wiemy, mogę pominąć fazę staged i od razu wykonać sava (commit a file):
git commit -am ”Rozdział pierwszy skończony”
Pisanie książki idzie bardzo sprawnie. Aktualnie jestem w trakcie pisania rozdziału drugiego. Oczywiście mógłbym tak savować (robić commity) do końca, ale wolę uzyskać większą bardziej przejrzystą historię zapisów. Dlatego właśnie rozdział 2 i każdy następny zostanie przypisany do innego branch-u:
git checkout -b PiszeRozdzialDrugi
(mogę też wykonać takie operacje --> , tworzę branch --> git branch PiszeRozdzialDrugi -- Teraz przełączam się na ten branch--> git checkout PiszeRozdzialDrugi).
W ten sposób stworzyłem kolejny branch o nazwie PiszeRozdzialDrugi i jednocześnie przełączyłem się na ten branch. Oznacza to tylko tyle, że teraz wszystkie zmiany (savy/commity) będą dokonywane w tym branchu. A jeszcze jaśniej powiedzmy, że do rozdziału 2 został stworzony oddzielny katalog i cała historia (wszystkie wersje/savy) będzie właśnie tutaj zapisywana.

Stworzyliśmy branch (gałąź), ale i tak należy wykonać commita(sava)
git commit -am ”Rozdział drugi start”
Proponuje teraz dla treningu napisać 10 rozdziałów, każdy zapisany w oddzielnym branchu. Dodatkowo wykonać przynajmniej 2 commity na rozdział.
Warto zanotować, że możliwe jest także stworzenie czystego branchu bez żadnych plików. Pytanie, w jakim celu miałbyś to robić? . Otóż teraz każdy rozdział jest zapisany w oddzielnym branchu, ale posiada także tekst poprzednich rozdziałów. Więc jeśli zechcesz to możesz każdy branch przeznaczać tylko na dany rozdział.
git checkout --orphan DanyRozdzial --> tworzysz i przełączasz sie.
Niestety jest pewien minus tego rozwiązania, pliki w katalogu trzeba ręcznie skasować dodatkowo oczyścić stan staged git rm--cached plik/pliki. Plusem natomiast jest historia, w logu będą widoczne tylko commity dla tego brancha (ale to tak a propos ;) ).
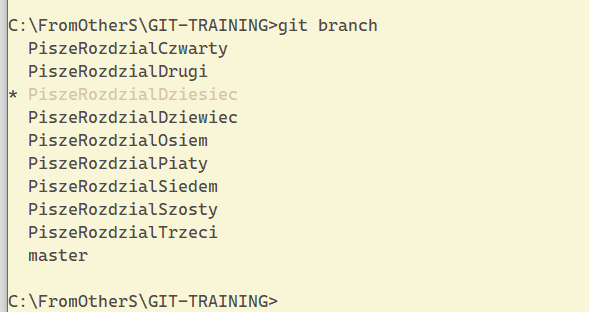
Wpisując git branch, otrzymasz wszystkie branche, jakie do tej pory stworzyłeś. U mnie wygląda to następująco:
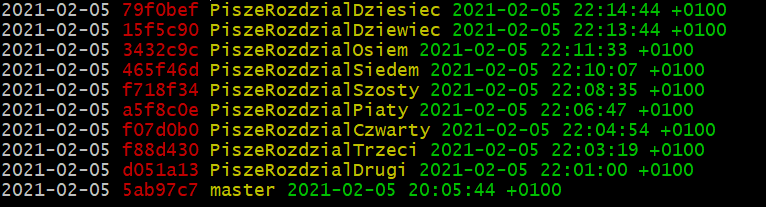
Natomiast całą historię commitów (savów) uzyskujesz poleceniem git log (spacja następna strona, q -> wyjście ).
lub ładniej w jednej linii --> git log --pretty=oneline
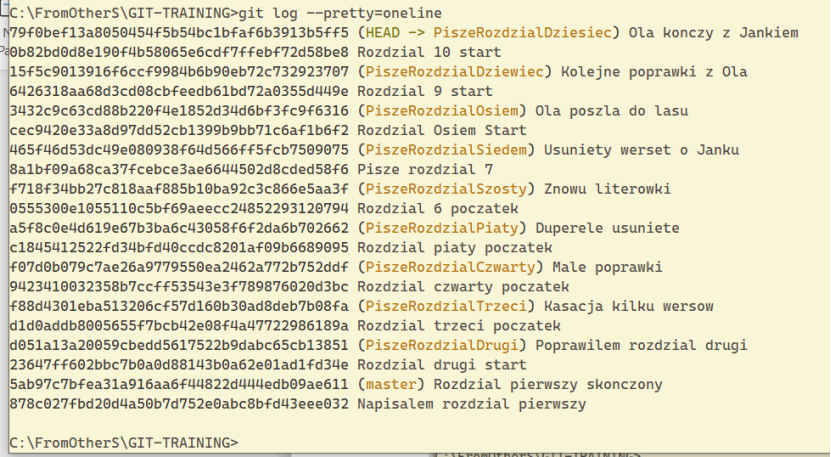
Cóż widać dzięki tej komendzie ?, unikatowy hashcommita, nazwę branch-u oraz tekst commitu (nazwę savu). Dodatkowo poprzez słowo HEAD wiesz, gdzie aktualnie się znajdujesz.
Historię commitów (savów) możemy uzyskać na naprawdę wiele sposobów np :
git log --pretty=format:"%h -, %cd :%s" (daje nam --> skrócony hash, datę i tekst commitu) :
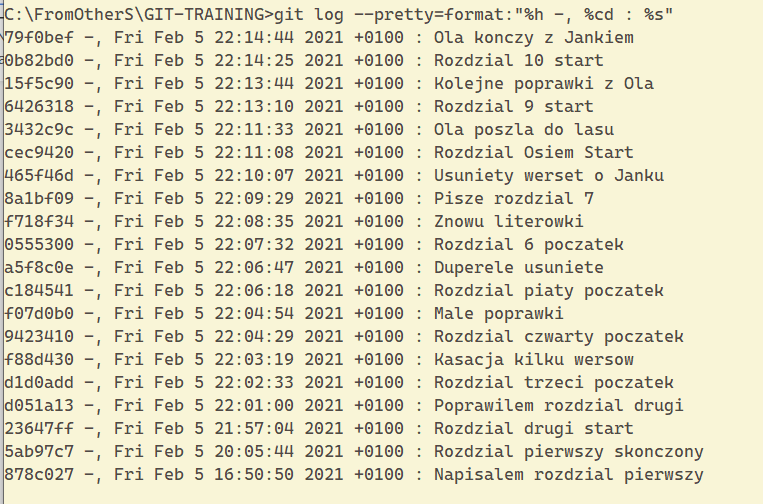
Możliwy jest także listing wszystkich commitów pomiędzy dwoma branchami (komenda służy do czegoś innego, ale w tym przypadku sprawdza się ;) ) np.:
git log --cherry jeden_branch..drugi_branch
Natomiast wszystkie czynności, jakie wykonałeś na danym repozytorium włącznie z datą stworzenia:
git reflog --date=local--> (sam reflog wyświetla wszystkie operacje, dalej to modyfikatory)
lub git reflog --date=local--all
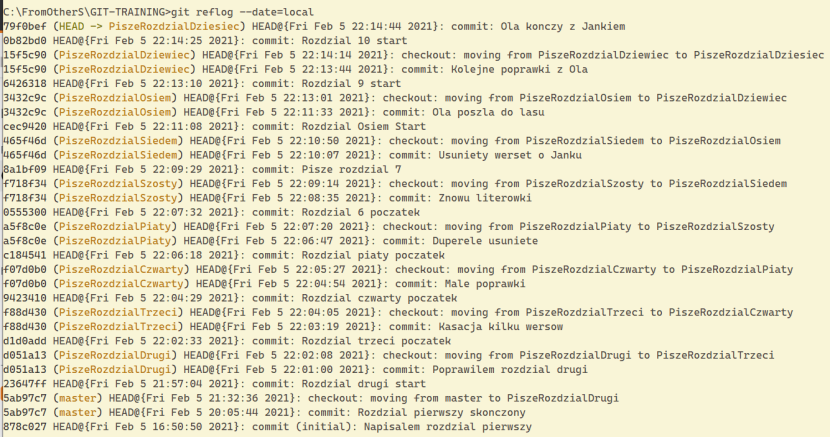
Lub historia dla danego branch-a
git reflog --date=local PiszeRozdzialSiedem
Dotychczas używałem git-a w zwykłym windowscommandprompt (cmd), teraz dla odmiany kliknij prawym klawiszem myszy w katalogu z projektem i wybierz:
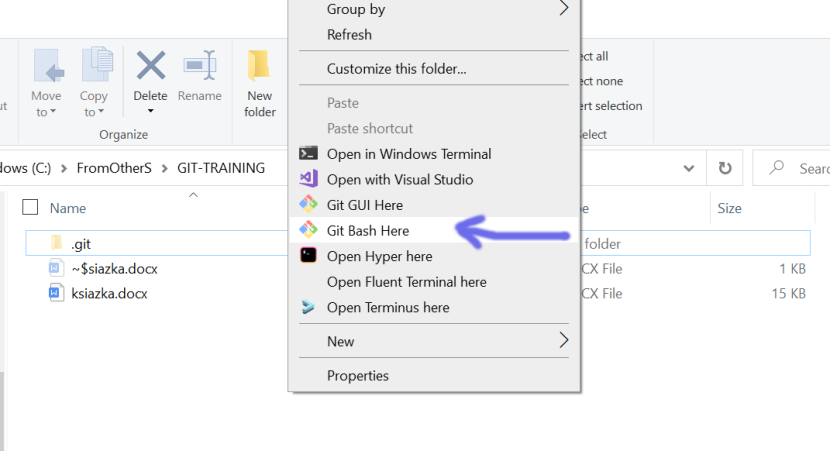
Dlaczego akurat Git Bash? , umożliwi skorzystanie z git-a w szerszym zakresie, a jeszcze inaczej uruchomisz te polecenia, które nie chcą poprawnie działać w cmd np.
git for-each-ref --sort=-committerdate refs/heads/ git for-each-ref --sort=-committerdaterefs/heads/ --format='%(committerdate) %(refname:short)'
Dzięki tej komendzie otrzymałeś dokładną datę utworzenia w gicie danego branchu.

lub też w ten sposób i z kolorem:
git for-each-ref --sort=-committerdaterefs/heads/ --format='%(authordate:short) %(color:red)%(objectname:short) %(color:yellow)%(refname:short) %(color:green)%(committerdate:iso)'
Porównałem pracę z gitem do grania w gry komputerowe a konkretnie do zapisywania i wczytywania savów (stanu gry).
Samo zapisywanie stanów w gicie jest całkiem proste. Jeśli natomiast zajdzie potrzeba wczytania jednego z poprzednich savów(commitów/branchów) to niestety sytuacja się trochę komplikuje. Tak jak to w gicie bywa, sposobów na wykonanie danej czynności jest wiele. Podobnie jest z powrotem do jednego z wcześniejszych zapisów.
Myślę, że wczytanie poprzedniego sava(commita) dobrze jest wykonać poprzez stworzenie nowego branchu z jednoczesnym przypisaniem do niego wybranego loadu(wybrany commit do wgrania) :
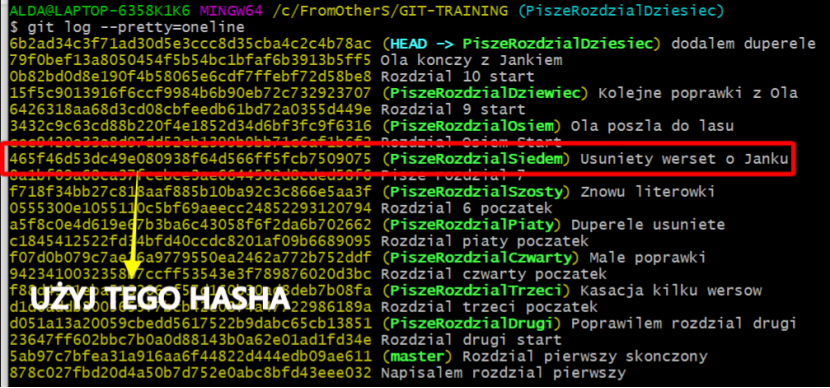
git checkout -b nowy_branch465f4
Do przeglądania historii proponuje jednak używać gita z reflogiem. Dotychczas git log wyglądał bardzo ładnie, jednak po operacjach wgrywania dawnych savów(commitów) możesz się pogubić.
WGRYWANIE POPRZEDNICH COMMITÓW
Możesz cofnąć się również o kilka pozycji do tyłu np. 5
git checkout -b nowy_branchHEAD~5
Nie polecam, ale można i tak:
git checkout hash_commita
lub
git checkout HEAD~2 -> 2 oznacza, o ile commitów chcesz się cofnąć.
To już trochę bardziej zaawansowany temat, ale znajdziesz się w stanie deteach HEAD. Krótko mówiąć, możesz wykonać commita. Natomiast w tym momencie nie zmieniaj branchu. Jeśli tak zrobisz, nic nie zostanie zapamiętane. Dlatego najpierw utwórz nowy branch, a następnie przejdź na niego:
git checkout -b nowy_branch
Natomiast jeśli chcesz wrócić w poprzednie miejsce bez żadnej zmiany --> git switch-
Kolejne rozwiązanie na wgranie commita/loada to twardy reset (zlikwidujesz wszystkie commity/savy do tego hasha, w teorii cofniesz się bez możliwości powrotu)
git reset --hard 465f4
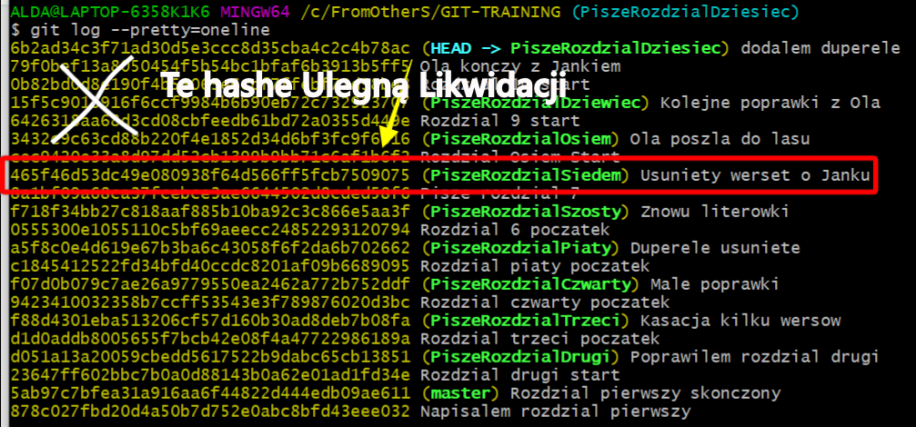
Tak naprawdę można wrócić do poprzedniego stanu, jednak nie chcę poświęcać zbyt dużo czasu na zbyt głębokie zanurzanie się w gicie. Zwróć jednak uwagę, na co wskazuje HEAD -->. Można się spodziewać, że powinien to być branch PiszeRozdzialSiedem, zgadza się ?. A jednak wskazuje inaczej.
Wszystkim nam zdarzają się pomyłki. Może się więc zdarzyć, że po wykonaniu sava(commita) zechcesz go skasować. Pomyślisz, nie ma problemu, robię twardy reset. Lepszym jednak rozwiązaniem jest:
git revert HEAD~1--> zostanie wykonany nowy commit, na bazie ostatniego dobrego. Natomiast stary zostanie w historii (zły teraz będzie o jeden wstecz).
PODSUMOWANIE
UTWORZENIE BRANCHa / GAŁĘZI
git branch nowy_branch
STWORZENIE BRANCHa na bazie COMMITu
git branch nowy_branch commit_id
STWORZENIE BRANCHa na bazie tagu
git branch nowy_branch TAG_NAME
KASOWANIE BRANCHa
git branch -d nazwa_branchu_do_kasacji
UTWORZENIE COMMITa
git commit -m "TWOJ Komentarz do commita"
USUNIĘCIE COMMITa (ostatniego)
git reset --hard hash_commita
LISTING WSZYSTKICH BRANCHy
git branch
ZMIANA BRANCHu NA INNY
git checkout inny_branch
UTWORZENIE INNEGO BRANCHU NA BAZIE AKTUALNEGO
git checkout -b nowy_branch
STWORZENIE PUSTEGO BRANCHU OSIEROCONEGO
git checkout --orphan pusty_branch
DODANIE PLIKU DO AKURAT UTWORZONEGO COMMITA
git add nowy_plik
git commit --amend
USUNIĘCIE PLIKU ZE STANU STAGED
git reset HEAD plik_do_usunięcia_ze_stanu_staged
lub
git restore --staged plik_do_usunięcia_ze_stanu_staged
USUNIĘCIE ZMIAN W PLIKU, KTÓRE NIE JEST w STAGED lub COMMIT
git checkout plik_ze_zmianami_do_usunięcia
lub
git restore plik_ze_zmianami_do_usunięcia